
What is Apache Spark?
Apache Spark is a unified analytics engine for large-scale data processing. It can efficiently process massive datasets across distributed clusters, offering:
- High Performance: Spark utilizes in-memory processing, making it significantly faster than traditional disk-based solutions.
- Scalability: Easily scales to handle large datasets across numerous nodes using its cluster architecture.
- Fault Tolerance: Spark automatically handles node failures and redistributes tasks for uninterrupted processing.
- Unified Platform: Supports diverse data sources (structured, unstructured, and semi-structured) and various processing needs (streaming, real-time, batch).
What is top use cases of Apache Spark?
Some of the top use cases for Apache Spark are:
- Big Data processing: Spark enables processing and analysis of large volumes of data, making it popular in the Big Data domain.
- Machine Learning: Spark’s MLlib library supports scalable machine learning tasks, including classification, regression, clustering, and recommendation systems.
- Streaming Analytics: Spark Streaming allows real-time analytics by processing data in batches or streams.
- Graph Processing: Spark GraphX provides an API for graph computation and analytics.
- Interactive Data Analysis: Spark SQL provides a programming interface to work with structured data using SQL queries.
What are feature of Apache Spark?
Features of Apache Spark:
- Speed: Spark performs data processing in-memory, resulting in faster execution compared to traditional disk-based systems.
- Ease of Use: Spark offers APIs in Scala, Java, Python, and R, making it accessible to a wide range of developers.
- Fault Tolerance: Spark automatically recovers from failures, ensuring reliable and consistent data processing.
- Scalability: It can efficiently handle large-scale datasets as it can distribute computations across a cluster of machines.
- Flexibility: Spark offers a variety of libraries and tools for different use cases, allowing seamless integration of various data processing tasks.
What is the workflow of Apache Spark?
Apache Spark follows a distributed processing workflow, which typically involves the following steps:
- Data Ingestion: Data is collected or imported from various sources, such as files, databases, or streaming systems.
- Data Transformation: The data is transformed and cleaned to prepare it for the desired analysis or processing.
- Data Analysis/Processing: Spark’s APIs are used to perform computations, analytics, or machine learning tasks on the transformed data.
- Data Visualization/Presentation: The results of the analysis are presented through visualizations, reports, or further processing.
How Apache Spark Works & Architecture?
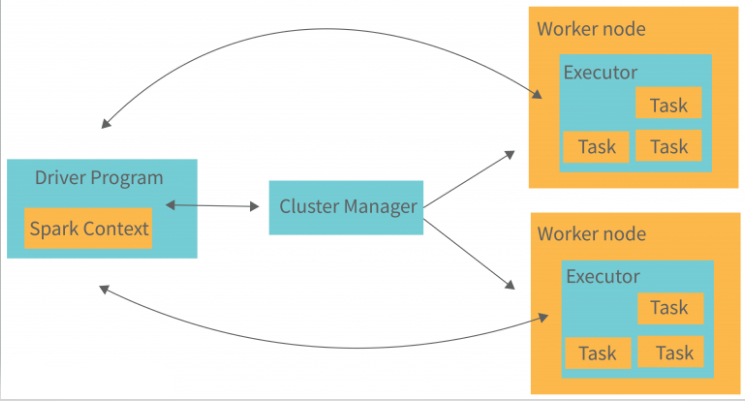
Apache Spark works like this:
The Spark Driver: It’s like the main manager. It organizes tasks and oversees the whole process. Spark divides work into smaller parts called jobs and sends them to different groups of workers in a cluster. The driver also creates gateways, called Spark contexts, which help keep an eye on the jobs and connect to the Spark cluster.
Spark Contexts: Think of them as gateways that supervise jobs in the cluster and connect everything together. All the actions in Spark happen through these contexts.
Spark Sessions: Each session in Spark has a Spark context. The drivers in Spark manage various components to get jobs done in clusters. They use different types of cluster managers to connect worker nodes where the actual work happens. Jobs get split into stages and then into smaller tasks that are scheduled to be executed.
Spark Executors: These guys do the actual work. Executors run the tasks assigned to them by the driver. They start by registering with the driver and then get time slots to do their work. Executors load data, execute tasks, and store temporary data while they’re active. When they’re not needed, they become idle.
Cluster Managers: They work alongside the driver to handle how jobs get done and where data is stored temporarily. Executors connect with the drivers, get slots to work on tasks, and handle data transfer. They’re constantly added and removed as needed.
How to Install and Configure Apache Spark?
To install Apache Spark, you can follow these general steps:
- Download the Spark distribution package from the official website (https://spark.apache.org/downloads.html) or use a package manager.
- Extract the downloaded package to your desired directory.
- Set up the required environment variables such as JAVA_HOME and SPARK_HOME.
- Optionally, configure Spark properties according to your cluster setup.
- Start using Spark with the provided scripts or by interacting with the available APIs.
Step by Step Tutorials for Apache Spark for hello world program
Here is a simple example of a “Hello, World!” program in Spark using Scala:
import org.apache.spark._
object HelloWorld {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Hello world")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Seq("Hello", "world"))
println(rdd.collect().mkString(", "))
}
}
In this example, we first import the necessary Spark classes. Then we define a main method where we create a SparkConf object and pass an app name to it. Next, we create a SparkContext object, which is the entry point to any functionality in Spark. We then create an RDD (Resilient Distributed Dataset) from a sequence of strings. Finally, we print out the contents of the RDD by calling collect() to bring the data to the driver program and mkString() to convert the array of Strings into a single String.