Source:-venturebeat.com
KYLE WIGGERS@KYLE_L_WIGGERS JUNE 25, 2019 6:59 AM
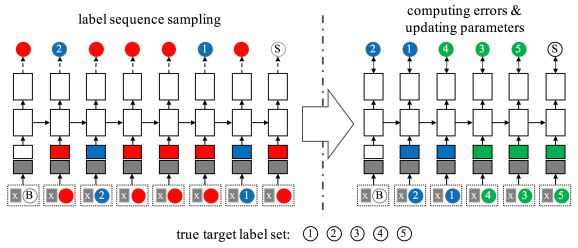
Above: A graph illustrating Amazon’s multilabel classification approach.
Image Credit: Amazon
MOST READ
Machine learning helps Microsoft’s AI realistically colorize video from a single image
Microsoft announces OneDrive Personal Vault for sensitive files
VB Event Transform 2019: Hear from the movers and shakers in AI
Lightyear One is a solar car with a range of 450 miles
Multilabel classifiers are the bedrock of autonomous cars, apps like Google Lens, and intelligent assistants from Amazon’s Alexa to Google Assistant. They map input data into multiple categories at once — classifying, say, a picture of the ocean as containing “sky” and “boats” but not “desert.”
In pursuit of more computationally efficient classifiers, scientists at Amazon’s Alexa AI division recently experimented with an approach they describe in a preprint paper (“Learning Context-Dependent Label Permutations for Multi-Label Classification”). They claim that in tests their multilabel classification technique outperforms four leading alternatives using three data sets and demonstrates improvements on five different performance measures.
Recommended Videos
Volume 0%
Researchers Describe Newly Discovered See-Through Frog
U.S. National Lab Prepares to Send Research Projects to I.S.S.
Bill Gates Has ‘Breakthrough’ In Probiotic Research
IBM Research Lead: Early Blood Test for Alzheimer’s May Be Possible Through AI
“The need for multilabel classification arises in many different contexts. Originally, it was investigated as a means of doing text classification [but since then], it’s been used for everything from predicting protein function from raw sequence data to classifying audio files by genre,” wrote Alexa AI group applied scientist Jinseok Nam in a blog post. “The challenge of multilabel classification is to capture dependencies between different labels.”
These dependencies are often captured with a joint probability, which represents the likelihood of any combination of probabilities for all labels. However, Nam notes that calculating accurate joint probabilities for more than a handful of annotations requires an “impractically” large corpus.
Instead, he and colleagues used a recurrent neural network (RNN) — a type of AImodel that processes sequenced inputs in order so that the output corresponds to given input factors and thus automatically considers dependencies — to efficiently chain single-label classifiers. To prevent errors from occurring when the order of classifiers is rearranged, they trained a system to dynamically vary the order in which the chained classifiers process the inputs (according to the input data’s features), ensuring that the most error-prone classifiers relative to a particular input moved to the back of the chain.
The team explored two different techniques, the first of which used an RNN to generate a sequence of labels for a particular input. Erroneous labels were discarded while preserving the order of correct ones, and omitted labels were appended to the resulting sequence. The new sequence became the target output, which the researchers used to retrain the RNN on the same input data.
“By preserving the order of the correct labels, we ensure that classifiers later in the chain learn to take advantage of classifications earlier in the chain,” wrote Nam. “Initially, the output of the RNN is entirely random, but it eventually learns to tailor its label sequences to the input data.”
The second technique leveraged reinforcement learning — an AI training technique that employs rewards to drive software policies toward goals — to train an RNN to perform dynamic classifier chaining.
In the aforementioned validation tests, which measured the accuracy of the classifiers’ various labels, the researchers say their best-performing system — which combined the outputs of two dynamic-chaining algorithms to produce a composite classification — outperformed four baselines by a minimum of 2% and in one instance by nearly 5%.