Source – https://bdtechtalks.com/
This article is part of our reviews of AI research papers, a series of posts that explore the latest findings in artificial intelligence.
Most artificial intelligence researchers agree that one of the key concerns of machine learning is adversarial attacks, data manipulation techniques that cause trained models to behave in undesired ways. But dealing with adversarial attacks has become a sort of cat-and-mouse chase, where AI researchers develop new defense techniques and then find ways to circumvent them.
Among the hottest areas of research in adversarial attacks is computer vision, AI systems that process visual data. By adding an imperceptible layer of noise to images, attackers can fool machine learning algorithms to misclassify them. A proven defense method against adversarial attacks on computer vision systems is “randomized smoothing,” a series of training techniques that focus on making machine learning systems resilient against imperceptible perturbations. Randomized smoothing has become popular because it is applicable to deep learning models, which are especially efficient in performing computer vision tasks.
But randomized smoothing is not perfect. And a new paper accepted at this year’s Conference on Computer Vision and Pattern Recognition (CVPR), AI researchers at Tulane University, Lawrence Livermore National Laboratory, and IBM Research shows that machine learning systems can fail against adversarial examples even if they have been trained with randomized smoothing techniques. Titled “How Robust are Randomized Smoothing based Defenses to Data Poisoning?” the paper sheds light on previously overlooked aspects of adversarial machine learning.
Data poisoning and randomized smoothing
One of the known techniques to compromise machine learning systems is to target the data used to train the models. Called data poisoning, this technique involves an attacker inserting corrupt data in the training dataset to compromise a target machine learning model during training. Some data poisoning techniques aim to trigger a specific behavior in a computer vision system when it faces a specific pattern of pixels at inference time. For instance, in the following image, the machine learning model will tune its parameters to label any image with the purple logo as “dog.”
Other data poisoning techniques aim to reduce the accuracy of a machine learning model on one or more output classes. In this case, the attacker would insert carefully crafted adversarial examples into the dataset used to train the model. These manipulated examples are virtually impossible to detect because their modifications are not visible to the human eye.
Research shows that computer vision systems trained on these examples would be vulnerable to adversarial attacks on manipulated images of the target class. But the AI community has come up with training methods that can make machine learning models robust against data poisoning.
“All previous data poisoning methods assume that the victim will use the standard training procedure of minimizing the empirical error on the training data,” Akshay Mehra, Ph.D. student at Tulane University and lead author of the paper, told TechTalks. “However, the adversarial robustness community has highlighted that minimizing the empirical error is not suitable for model training since models trained with it are vulnerable to adversarial attacks. Several works have been published that try to improve the adversarial robustness of the models. Of these works, training procedures that can produce certifiably robust models are of the most interest due to the adversarial robustness guarantees of the models, trained using these methods.”
Random smoothing is a technique that cancels out the effects of data poisoning by establishing an average certified radius (ACR) during the training of a machine learning model. If a trained computer vision model classifies an image correctly, then adversarial perturbations within the certified radius will not affect its accuracy. The larger the ACR, the harder it becomes to stage an adversarial attack against the machine learning model without making the adversarial noise visible to the human eye.
Experiments show that deep learning models trained with random smoothing techniques maintain their accuracy even if their training dataset contains poisoned examples.
In their research, Mehra and his co-authors assumed that a victim has used random smoothing to make the target robust against adversarial attacks. “In our work, we explored three popular training procedures (Gaussian data augmentation, smooth adversarial training, and MACER) which have been shown to increase certified adversarial robustness of the models as measured by the state-of-the-art certification method based on randomized smoothing,” Mehra says.
Their findings show that even when trained with certified adversarial robustness techniques, machine learning models can be compromised through data poisoning.
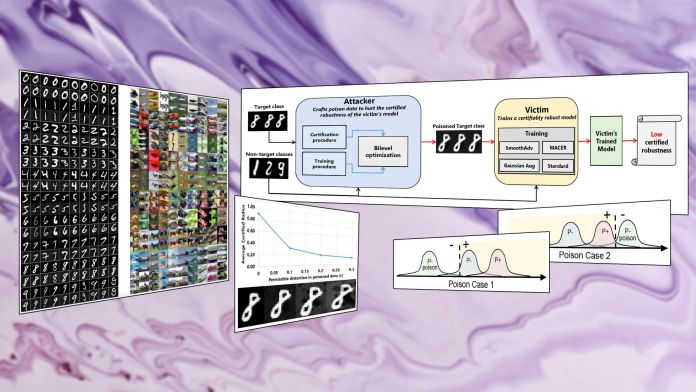
Poisoning Against Certified Defenses and bilevel optimization
In their paper, the researchers introduce a new data poisoning method called “Poisoning Against Certified Defenses” (PACD). PACD uses a technique known as “bilevel optimization,” which achieves two goals: create poisoned data for models that have undergone robustness training and pass the certification procedure. PACD produces clean adversarial examples, which means the perturbations are not visible to the human eye.
“A few previous works have shown the effectiveness of solving the bilevel optimization problem to achieve better poisoning data,” Mehra says. “The difference in the formulation of the attack in this work is that instead of using the poison data to reduce the model accuracy we are targeting certified adversarial robustness guarantees obtained from state-of-the-art certification procedure based on randomized smoothing.”
The bilevel optimization process takes a set of clean training examples and gradually adds noise to them until they reach a level that can circumvent the target training technique. The ingenuity behind this data poisoning technique is that researchers were able to create a machine learning algorithm that optimizes the adversarial noise for the specific type of robustness training method used in the target model. The algorithm that creates the adversarial example is called ApproxGrad, and it can be adjusted for different robustness training methods.
Once the target model is trained on the tainted dataset, its ACR will be reduced considerably, and it will be highly vulnerable to adversarial attacks.
“In our approach, we explicitly generated poison data that when used for training, will lead to models with low certified adversarial robustness,” Mehra says. “To do this we used the training procedures that produce models with high certified adversarial robustness as our lower-level problem. The attacker’s objective (upper-level problem) is to lower the guarantees produced by the certification procedure. By approximately solving this bilevel optimization problem we were able to generate poison data that could significantly hurt the certified adversarial robustness guarantees of the models. The lowered guarantees lead to a loss of trust in the model’s prediction at test-time.”
The researchers applied PACD to the MNIST and CIFAR datasets and tested it on neural networks trained with all three popular adversarial robustness techniques. In all cases, PACD data poisoning resulted in a considerable decrease in the average certified radius of the trained model, making it vulnerable to adversarial attacks.
The AI researchers also tested to see whether a poisoned dataset targeted at one adversarial training technique would prove to be effective against others. Interestingly, their findings show that PACD transfers across different training techniques. For instance, even if a poisoned dataset has been optimized for gaussian data augmentation, it will still be effective on machine learning models that will go through the MACER and smooth adversarial training processes.
“We demonstrate, through transfer learning experiments, that the generated poison data works to reduce the certified adversarial robustness guarantees of models trained with different methods and also models with different architectures,” Mehra says.
But while PACD has proven to be effective, it comes with a few caveats. Adversarial attacks that assume full knowledge of the target model, including its architecture and weights, are called “white box attacks.” Adversarial attacks that only need access to the output of a machine learning model are “black box attacks.” PACD stands somewhere in between the two ends of the spectrum. The attacker needs to have some general knowledge of the target machine learning model before formulating the poisoned data.
“Our attack is a grey box attack since we are assuming knowledge of victim’s model architecture and training method,” Mehra says. “But we don’t assume knowledge of the particular weights of the network.”
Another problem with PACD is the cost of producing the poisoned dataset. ApproxGrad, the algorithm that generates the adversarial examples, becomes computationally expensive when applied to large machine learning models and complicated problems. In their experiments, the AI researchers focused on small convolutional neural networks trained to classify the MNIST and CIFAR-10 datasets, which contain no more than 60,000 training examples. In their paper, the researchers note, “For datasets like ImageNet where the optimization must be performed over a very large number of batches, obtaining the solution to bilevel problems becomes computationally hard. Due to this bottleneck we leave the problem of poisoning ImageNet for future work.”
ImageNet contains more than 14 million examples. A machine learning model that can perform well on the ImageNet dataset requires a convolutional neural network with dozens of layers and millions of parameters. Accordingly, creating PACD data would require large resources.
“Solving bilevel optimization problems can be computationally expensive, especially when using very large datasets and deep models,” Mehra says. “However, in our paper, we show that attacks generated against moderately deep models transfer well to much deeper models. It would be interesting to see if attacks generated against a portion of the large training data also work well on the entire training data.”
Today, machine learning applications have created new and complex attack vectors in the millions of parameters of trained models and the numerical values of image pixels, audio samples, and text documents. Adversarial attacks are presenting new challenges for the cybersecurity community, whose tools and methods are centered on finding and fixing bugs in source code.
The PACD technique shows that poisoned data can render proven adversarial defense methods ineffective. Mehra and his co-authors warn that data quality is an underrated factor in assessing adversarial vulnerabilities and developing defenses.
For instance, a malicious actor can develop a tainted dataset and deploy it online for others to use in training their machine learning models. Alternatively, the attacker can insert poisoned examples into crowdsourced machine learning datasets. The adversarial perturbations are imperceptible to the human eye, which makes it extremely difficult to detect them. And automated tools that vet software security can’t detect them.
PACD has important implications for the machine learning community. Machine learning engineers should be more careful about the datasets they use to train their models and make sure the source is trustworthy. Organizations that curate datasets for machine learning training should be more careful about the provenance of their data. And companies such as Kaggle and GitHub that host datasets and machine learning models should start thinking about ways to verify the quality and security of their datasets.
We still don’t have complete tools to detect adversarial perturbations in training datasets. But securing the pipeline for accessing and managing machine learning training datasets can be a good first step in preventing the kind of data poisoning measures Mehra and his co-authors describe in their paper.
The Adversarial ML Threat Matrix, introduced last October, provides solid guidelines on finding and fixing possible holes in the training and deployment pipeline of machine learning models. But a lot more needs to be done. Another useful tool is a series of deep learning trust metrics developed by AI researchers at the University of Waterloo, which can find classes and areas where a computer vision system is underperforming and might be vulnerable to adversarial attacks.
“Through this work, we want to show that advances in certified adversarial robustness are dependent on the quality of the data used for training the models,” Mehra says. “Current methods for detecting data poisoning attacks may not be sufficient when attacker adds imperceptibly distorted data. We need more sophisticated methods to deal with this and is a direction for our future research.”