Source – https://www.geospatialworld.net/
There has been substantial progress in building a Machine Learning (ML) methodology for Earth Observation (EO) data analysis; however, experts worldwide face many challenges while using ML algorithms on EO data.
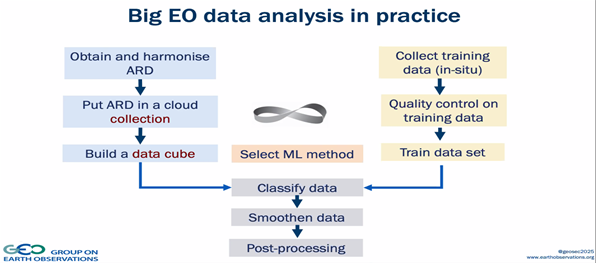
For ML models to work, two processes work simultaneously. First, tons of data is captured from EO satellites, which is processed to make it application-ready. This data is called application-ready data (ARD), put in Cloud and organized into different datasets called data cubes. Secondly, the training data is collected to train models. Once both datasets are organized, an appropriate ML model is selected to classify, smoothen, and process the data to get valuable insights.
Using multiple ML algorithms on large volumes of EO data ensures reliable and conclusive results, thereby easing the process to prove or disprove a given hypothesis. While the benefits are many, EO satellite data’s abundant availability makes it tricky to run ML models and algorithms efficiently. Currently, we have a ton of datasets like Sentinel 2, Sentinel 3, Landsat 8, and SkySat, to name a few, which provide more than 2 petabytes (PB) of data every day. Thus, while many ML models operate efficiently on sample models, they fail to represent actual reality.
One of the most critical challenges faced in deploying ML models appropriately is the massive volume of data collected. Prof. Dr. Gilberto Camara, Secretariat Director, GEO, mentioned during the discussion that the data derived from EO satellites should be enough to cover all the categories and details a project requires explicitly. However, data labeling of the number of categories is crucial, which defines the behavior of the classifier modeling the data.
Data labeling
ML requires labels to understand data better, but natures’ diversity limits the application of ML algorithms. The currently available categorization is often found not enough to label data. For a basic understanding, we take the example of using ML algorithms for EO data of forests –
As depicted in the above image, how one defines a forest label is different for different places. Forest is a single label, but it has several variations, ranging from Boreal forest to Tropical forest. One may think this problem can be easily solved by breaking the label down into several small labels. Supposedly, if one were to break the term forest into eight different labels, the problem of finding good samples to train the ML algorithm is multiplied by eight. Hence, if we required 1,000 samples for the forest, in the above scenario, we would require 8,000 samples for the same, which complicates the matter. Thus, to describe nature appropriately, it is essential to ensure whether the labels used to define nature are consistent with the ML models.
Time as an element
In the case of forests, EO data is being used to monitor a forest’s condition – particularly deforestation. Deforestation is not a one-time process but is the result of a series of steps happening over time. In the ML context, it involves working with both Space and time. To understand it better, we can look at the diagram below, which explains how a forest evolves. A forest can grow in any of the ways mentioned below; for instance, it can be conserved throughout time, as in Fig A (1). There can be deforestation, or there can be afforestation in deforested land with time, as in Fig A (3).
To sum it up, one needs to measure what exists in a certain place at a certain point in time and determine the events that have happened in that particular location over time. Hence, to work with Space and time, we require spatial-temporal models. Modeling events and time is key for big EO data analysis, but ML has a hard time dealing with the change.
A solution to the above challenge is to use Geospatial Semantics for EO data analysis. Herein, EO data is organized using a logical view, including indexing and/or ingestion, rather than arranging it in three dimensions: time, longitude, and latitude. The significance of ingesting data is that it can be collected in a query-optimized way. Certain access patterns can be achieved more efficiently, such as spatial analysis or time series analysis.
Other technical challenges
The other technical challenges that data analysts and processors face while feeding the images to the ML models, like:
- Resolution– Different satellites provide different resolutions of images ranging from 500m provided by MODIS to 0.3 m by WorldView. Additionally, different datasets have different formats, such as JPEG2000 and GeoTIFF, among others. Thus, the processor must learn to work with different resolutions and formats. This problem can be partly solved by third-party software like Sentinel Hub, which harmonizes the Earth Observation data in one single format.
- often partly or fully covered by clouds. The Clouds make it difficult for any algorithm and processor to derive useful insights from the satellite imageries. Therefore, the processor should mask these clouds so that these white spots or shadows do not distort the signals.
- Geometrical accuracy– Satellite images often twitch because geo-referenced points used for georeferencing the image are not perfect. While this has gotten better over the past few years, but it still could not be expected that one pixel will represent one point of the world.
Conclusion
Artificial Intelligence experts face many challenges while applying ML algorithms on EO data, affecting every phase of the data processing and analysis, ranging from collecting training data to deriving valuable insights from it. Recently, MKAI Technical Forum conducted a webinar on using AI on EO data. The webinar discussed how ML models are used to classify, smoothen and post-process the humongous volumes of EO data. A few ways to deal with these challenges would be to build robust and geographically diverse training data sets, include Geospatial Semantics in the process, and harmonize the data using various third-party software available in the market.