Source: infoq.com
Researchers from Google AI recently open-sourced the Reformer, a more efficient version of the Transformer deep-learning model. Using a hashing trick for attention calculation and reversible residual layers, the Reformer can handle text sequences up to 1 million words while consuming only 16GB of memory on a single GPU accelerator.
In a paper accepted for oral presentation at ICLR 2020, the team gave a detailed description of the model and several experiments. Since two of the major sources of large memory requirements of a standard Transformer model are the attention calculations and the network layer activations, the team applied space-saving techniques to each of these areas. To reduce the requirement for attention, Reformer uses approximate attention calculation via locality-sensitive hashing (LSH), reducing the memory requirements from O(N2)O(N2) to O(NlogN)O(NlogN), where N is the length of the input sequences. Using reversible layers reduces the need to store activations for every network layer; instead, only the last layer’s activations need to be stored. The combination of the two techniques allows for training deeper models on longer input sequences, without requiring large clusters of GPUs. According to the researchers,
With such a large context window, Transformer could be used for applications beyond text, including pixels or musical notes, enabling it to be used to generate music and images.
The Transformer is a deep-learning architecture that is used by several state-of-the art natural-language processing (NLP) systems such as BERT, RoBERTA, and GPT-2. The input to a Transformer is a sequence of data items such as the words in a sentence. The output is likewise a sequence; in the case of machine translation, for example, the output is the translation of the input sentence. The key to the Transformer’s operation is attention, which calculates the importance of each pair of words in the input. The complexity of the attention calculation thus grows as the square of the length of the input sequence. Given that the networks typically have many, often dozens, of layers, each with an attention component, the memory requirements for training often exceed the capacity of a single GPU, requiring a cluster of GPUs performing model-parallel training.
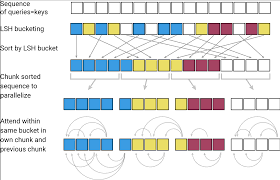
Reformer’s first improvement is to reduce the memory requirements for attention. The attention operation is a normalized dot-product of vectors followed by a softmax. Since the normalized dot-product effectively calculates the angular “distance” between vectors—that is, it calculates how much they are pointing in the same direction—and the softmax is weighted toward the largest of those values, the attention calculation can be simplified by only performing attention calculations on the vectors that are closest together in angular space. The research team’s insight here was to use a locality-sensitive hashing (LSH) function. These functions output the same hash code for vectors that are neighbors. Using LSH to group vectors by proximity and only compute attention among neighbors can reduce the attention complexity from O(N2)O(N2) to O(NlogN)O(NlogN), with only a few percentage points drop in accuracy.
The second improvement is to reduce the need to store activations of hidden layers. The standard backprop technique used in training neural networks requires the storage of these values. Researchers have found that deep networks—that is, networks with more layers—tend to perform better than shallower ones, and the memory cost of storing the activations increases linearly with the number of layers. Thus, while any given layer may only require a few GB of storage, large networks with dozens of layers can easily exceed the on-board capacity of a single GPU. Reformer solves this by implementing reversible layers. During backprop, a reversible layer can recover its own activations; given the activations of a previous layer, it can run its calculations in reverse. The Reformer model therefore only needs to store the activations of the last layer, with no effect on accuracy.
Transformer models such as BERT and GPT-2 have achieved state-of-the-art NLP results, but the cost of training these models has led to an ongoing effort to reduce their complexity while still retaining model accuracy. Last year, OpenAI introduced Sparse Transformers, with factorization of the attention mechanism to reduce complexity from O(N2)O(N2) to O(NN−−√)O(NN). Google recently released ALBERT, which has 89% fewer parameters than BERT, but loses some accuracy. In discussing the Reformer on Hacker News, one user stated:
This seems like a big deal. An asymptotic reduction in the resource explosion created by larger attention windows should allow the development of substantially more complex models here.
Reformer’s source code is available on GitHub as part of the Trax package.