Source – https://physicsworld.com/
Last year, the scientific community built thousands of machine learning models and other artificial intelligence systems to identify COVID-19 on chest X-ray and CT images. Some researchers were sceptical of the results: were the models identifying COVID-19 pathology or were they instead making decisions based on confounders such as arrows and other medically irrelevant features?
To answer this question, two medical students working toward their doctorates in computer science in Su-In Lee’s laboratory at the University of Washington rigorously audited hundreds of machine learning models intended for classifying chest X-rays as COVID-19-positive or COVID-19-negative. Results of their audit are reported in Nature Machine Intelligence.
The domain shift problem
The University of Washington researchers wanted to know whether or not published machine learning (ML) models were generalizable. A generalizable ML model will classify chest X-rays as COVID-19-positive or COVID-19-negative correctly no matter where the chest X-rays came from. A model that isn’t generalizable won’t perform well, for example, when it sees chest X-rays that were acquired at a different hospital.
Computer scientists call this drop in performance domain shift. Machine learning models affected by domain shift pick up on minute, systematic differences between datasets that are stronger and more obvious to the model than subtle indications of COVID-19 infection. These ML models then adopt shortcut learning, training on confounders like arrows and text labels and making spurious associations that emerge even when models are trained and tested on other datasets.
In this way, an ML model that uses shortcut learning will demonstrate domain shift and will not be generalizable, while an ML model that relies on medically relevant features to make decisions is more likely to be generalizable and maintain its performance across datasets.
Auditing, machine learning style
While ML models designed to classify chest X-rays tend to use similar architectures, training methods and optimization schemes, the first hurdle that the University of Washington researchers faced was recreating the published ML models.
“Models can differ in subtle ways…And instead of distributing trained models, researchers give out directions for how they made their models,” says Alex DeGrave, co-first author on the University of Washington study. “There’s a whole range of models that you could end up getting out of that set of directions due to randomness in the [model] training process.”
To reflect possible variations that might emerge during training, co-first authors DeGrave and Joseph Janizek, with their adviser and senior author Su-In Lee, first designed an ML model representative of those introduced in dozens of studies and then made minor adjustments to the representative model. They ultimately created and audited hundreds of models and classified thousands of chest X-rays.
Is it COVID-19 or just an arrow?
After introducing their models to new datasets and observing drops in classification performance indicative of domain shift and shortcut learning, the researchers decided to pinpoint the shortcuts themselves. This is challenging because the decisions made by ML models come from a “black box” – exactly how these models make classification decisions is unknown even to model designers.
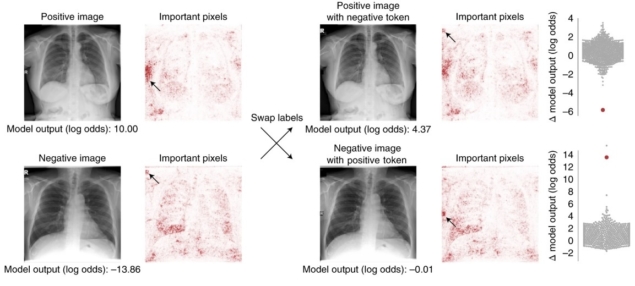
DeGrave and Janizek deconstructed this “black box” with saliency maps that highlight regions that a model deems important, applying generative methods that transform images, and by manually editing images. Some saliency maps showed medically relevant areas like the lungs, while others pointed to text or arrows on an image, or to an image’s corners, suggesting that the ML models learned and decided COVID-19 status based on these features rather than pathology.
To validate these results, the researchers applied generative methods to make COVID-19-negative chest X-rays look like COVID-19-positive chest X-rays and vice versa.
“We found that if we went back and fed these [altered] images into the original networks we were auditing, it would typically fool those networks into thinking that they were images from the opposite class,” DeGrave explains. “So that means that the things these generative networks were changing were indeed things that the networks we were auditing looked at.”
The researchers again found that model performance depended upon text markers when they swapped written text on pairs of images (one COVID-19-positive and one COVID-19-negative chest X-ray). The researchers’ experiments also revealed that model architecture had little impact on model performance.
“There’s a lot of focus in the literature, I think, on ‘we have the nicest, most interesting new architecture’. We found that actually has a limited impact…whereas working with the data, and changing the data, collecting better data, had a very sizable impact,” Janizek says.
Building and auditing trustworthy AI systems
The researchers’ results indicate the gravity of shortcut learning. They also point to a need for explainable artificial intelligence, which requires that decisions made by machine learning models be understandable and traceable by humans, going forward.
So, how can researchers build machine learning networks that learn from medically relevant features and are generalizable?
DeGrave and Janizek provide several suggestions. First, researchers should collect data prospectively and with the model’s goal in mind, and datasets should be balanced with good overlap. For example, each institution involved in a study should collect COVID-19-positive and COVID-19-negative data, not one or the other. Second, clinicians should be involved in study design and data collection, and researchers should work with clinicians to identify different kinds of confounders that the ML model might rely on. Third, ML models should be audited before they are applied elsewhere.
These suggestions alone are not enough to overcome shortcut learning, the researchers say, and more research is needed. For now, they hope that this study will spark a broader dialogue about the importance of auditing ML models and the need for explainable artificial intelligence. They also want people to be more aware of the kinds of mistakes machine learning models can make.
“There are methods to explain models and detect shortcuts, there are methods to try to improve models…Researchers need to be really thinking about how all of these methods connect to each other to build not just better methods, but a better ecosystem of methods that connect with each other and make it easy for model developers to build a model that we can trust and rely on,” says Janizek.