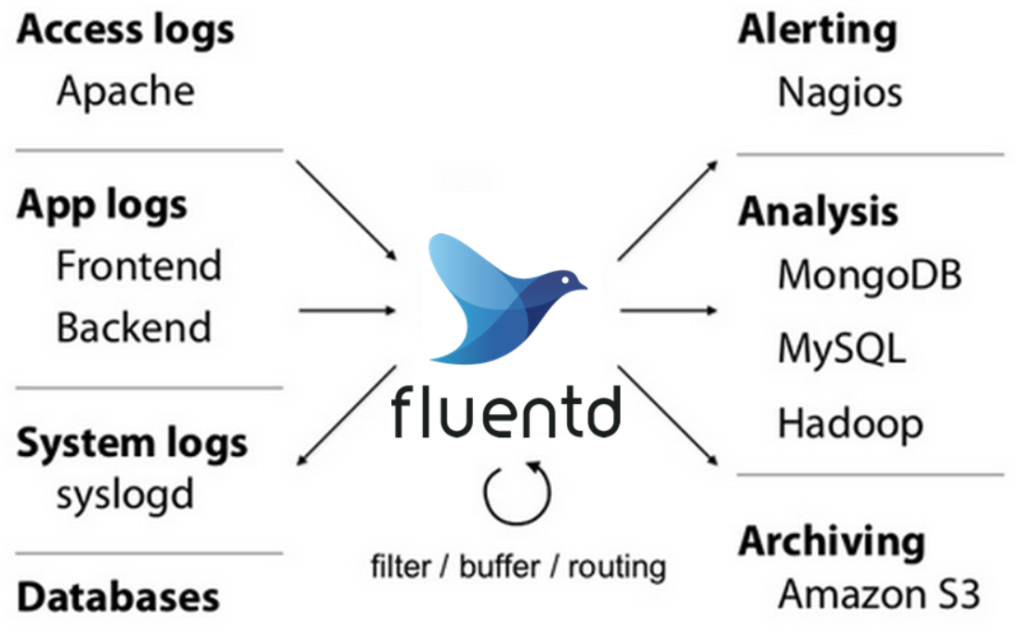
In today’s IT landscape, where data is generated from a myriad of sources, including applications, devices, and infrastructure, managing and processing this data efficiently has become critical. Fluentd is an open-source data collector that acts as a unified logging layer, allowing organizations to ingest, process, and deliver log data to a variety of storage and analytics destinations. Fluentd is designed to simplify the log management process while being highly scalable, flexible, and reliable.
Fluentd supports structured and unstructured data, making it suitable for use cases ranging from application performance monitoring to security and compliance. By enabling real-time log collection, filtering, and transformation, Fluentd helps teams gain actionable insights from their data and optimize operations. As part of the Cloud Native Computing Foundation (CNCF), Fluentd is widely used in modern cloud-native and containerized environments.
What is Fluentd?
Fluentd is an open-source data collector and log management tool that provides a unified way to ingest, transform, and forward data. Fluentd centralizes log collection from diverse sources, such as servers, applications, network devices, and containers, and routes the processed data to a variety of endpoints, including Elasticsearch, Amazon S3, Kafka, and other databases or analytics tools.
One of Fluentd’s standout features is its plugin-based architecture, which supports over 500 plugins. These plugins allow Fluentd to integrate seamlessly with different data sources and outputs, making it highly adaptable to various environments. Additionally, Fluentd supports real-time processing and enables organizations to structure unstructured data for better compatibility with downstream systems.
Top 10 Use Cases of Fluentd
- Centralized Log Aggregation
Fluentd collects logs from multiple systems and applications, centralizing them into a unified platform for easier analysis and management. - Application Performance Monitoring (APM)
Fluentd enables real-time monitoring of application logs to identify performance bottlenecks, errors, and user activity patterns. - Kubernetes and Container Logging
Fluentd integrates with Kubernetes to collect logs from containers and pods, providing insights into containerized environments. - Real-Time Data Streaming
Fluentd processes and streams data to platforms like Kafka, AWS Kinesis, or Google Pub/Sub for real-time analytics. - Cloud Resource Monitoring
Fluentd collects logs and metrics from cloud services, ensuring visibility into cloud-based resources and applications. - Security Information and Event Management (SIEM)
Fluentd forwards enriched log data to SIEM systems, aiding in threat detection and response. - IoT Data Collection
Fluentd gathers data from IoT devices, processes it in real-time, and routes it to analytics platforms for insights into device performance and usage. - Log Filtering and Transformation
Fluentd filters out unnecessary log data and enriches logs with metadata, such as timestamps or geolocation, for better analysis. - Compliance and Audit Logging
Fluentd ensures that logs are collected, stored, and formatted to meet regulatory requirements like GDPR, HIPAA, or PCI DSS. - Business Intelligence
Fluentd collects and processes data from business applications, providing insights into sales, customer interactions, and operational trends.
What Are the Features of Fluentd?
- Unified Logging Layer
Fluentd acts as a central logging hub, unifying log collection and processing across various systems and platforms. - Extensive Plugin Ecosystem
With over 500 plugins, Fluentd integrates with multiple data sources and destinations, including Elasticsearch, Splunk, and Hadoop. - Real-Time Data Processing
Fluentd processes logs and events in real-time, enabling quick responses to system changes or incidents. - Flexible Data Transformation
Transform raw log data into structured formats, such as JSON or XML, using Fluentd’s powerful filtering capabilities. - Cloud-Native Integration
Fluentd is optimized for cloud-native environments, integrating seamlessly with Kubernetes, Docker, and cloud platforms. - Fault Tolerance and Reliability
Fluentd includes buffering mechanisms to ensure that no data is lost during network interruptions or processing errors. - Low Resource Consumption
Fluentd is lightweight and efficient, making it suitable for resource-constrained environments. - Scalability
Fluentd can handle large-scale deployments by distributing workloads across multiple nodes or instances. - Open-Source and Customizable
Fluentd’s open-source nature allows organizations to tailor it to their specific needs with custom plugins and configurations. - Support for Structured and Unstructured Data
Fluentd can process data in various formats, making it versatile for different use cases and industries.
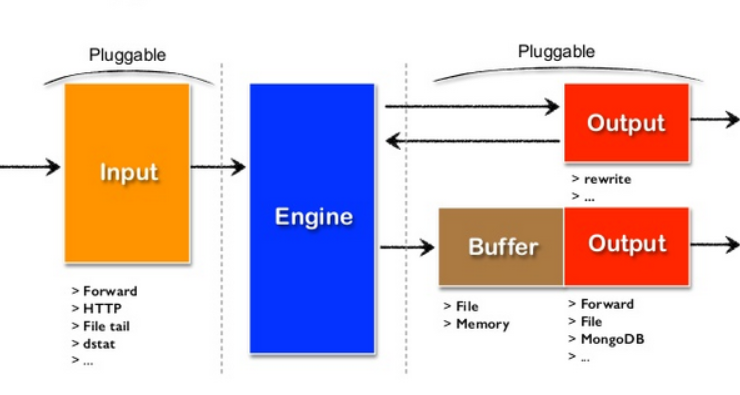
How Fluentd Works and Architecture
How It Works:
Fluentd operates as a flexible data pipeline with three main components: Input, Filter, and Output. It collects data from various sources, processes and enriches it through filtering, and routes it to one or more destinations for storage or analysis.
Architecture Overview:
- Input Plugins:
Fluentd collects data from sources like log files, APIs, message queues, and databases. Popular input plugins include Syslog, HTTP, and File. - Filter Plugins:
These plugins allow Fluentd to process, enrich, and transform data. Examples include grok patterns for log parsing and GeoIP for geolocation enrichment. - Buffering:
Fluentd uses an in-memory or disk-based buffer to temporarily store data during processing or network disruptions. - Output Plugins:
Data is sent to various endpoints, such as Elasticsearch, Kafka, or cloud storage, using Fluentd’s output plugins. - Tagging System:
Fluentd tags logs to facilitate routing and processing within its pipeline. - Monitoring and Metrics:
Fluentd includes built-in monitoring tools to track pipeline performance and detect bottlenecks.
How to Install Fluentd
Steps to Install Fluentd on Linux:
1.Install Fluentd:
Use the following script to install Fluentd on Ubuntu:
curl -fsSL https://toolbelt.treasuredata.com/sh/install-ubuntu-focal-td-agent4.sh | sh2. Verify Installation:
Check the Fluentd installation by running:
td-agent --version3. Configure Fluentd:
Edit the configuration file located at /etc/td-agent/td-agent.conf:
<source>
@type forward
port 24224
</source>
<match **>
@type stdout
</match>4. Start Fluentd Service:
Start the Fluentd service and enable it to run on boot:
sudo systemctl start td-agent
sudo systemctl enable td-agent5. Test Fluentd Setup:
Send sample logs to Fluentd using the fluent-cat command:
echo '{"message": "Hello Fluentd!"}' | fluent-cat test.logs6. Integrate Fluentd with Data Sources:
Add input and output configurations to integrate Fluentd with your log sources and destinations.
Basic Tutorials of Fluentd: Getting Started
1. Configuring Log Collection:
- Define a file input source:
<source>
@type tail
path /var/log/myapp.log
pos_file /var/log/td-agent/myapp.pos
tag myapp.logs
format none
</source>2. Adding Filters:
- Use filters to enrich logs with additional metadata:
<filter myapp.logs>
@type record_transformer
<record>
hostname ${hostname}
</record>
</filter>3. Forwarding Logs to Elasticsearch:
- Configure Fluentd to send logs to Elasticsearch:
<match myapp.logs>
@type elasticsearch
host localhost
port 9200
logstash_format true
</match>4. Monitoring Fluentd Pipelines:
- Enable the monitor agent to track pipeline performance:
<source>
@type monitor_agent
port 24220
</source>5. Using Fluentd in Kubernetes:
- Deploy Fluentd as a DaemonSet to collect logs from Kubernetes pods and nodes.