Introduction
In the world of data collection and logging, Fluentd is a robust open-source tool designed to unify the collection, filtering, and output of log data. Fluentd is a data collector that allows businesses and organizations to streamline their logging infrastructure by gathering logs from multiple sources, processing them, and sending them to various destinations such as databases, cloud storage, and analytics platforms. Its flexible architecture and scalability make it an essential tool for modern data pipelines.
What is Fluentd?
Fluentd is an open-source data collector that unifies log data collection and distribution across systems. It is designed to handle high volumes of data and is often used in log aggregation and centralized logging systems. Fluentd enables businesses to collect logs from various sources, transform them in real-time, and send them to different destinations for analysis and storage. Fluentd supports a large number of plugins for input, output, filtering, and processing, making it highly adaptable to various use cases.
Fluentd is particularly useful in cloud-native environments, where data streams are often distributed across multiple systems and services. It integrates well with platforms like Kubernetes, Docker, and cloud-based applications.
Top 10 Use Cases of Fluentd
- Log Aggregation and Centralization:
Fluentd is commonly used to aggregate logs from multiple sources such as web servers, databases, and cloud services into a single system, making it easier to monitor and analyze logs. - Real-Time Data Processing:
Fluentd enables real-time log processing, allowing organizations to monitor and respond to issues as they occur, reducing downtime and improving operational efficiency. - Monitoring Cloud-Based Applications:
Fluentd is ideal for aggregating logs from cloud environments like AWS, Google Cloud, and Azure, allowing businesses to monitor and troubleshoot cloud-native applications. - Application Performance Monitoring (APM):
Fluentd helps monitor application logs, providing insights into application performance, error tracking, and bottleneck detection. - Security Information and Event Management (SIEM):
Fluentd collects and processes security logs for real-time threat detection, auditing, and compliance monitoring, making it a key component in SIEM systems. - Data Integration for Analytics:
Fluentd integrates data from various sources and formats, enabling seamless data transfer to analytics platforms such as Elasticsearch, Splunk, or cloud-based data lakes. - Log Transformation and Parsing:
Fluentd is widely used for transforming logs into structured formats such as JSON, CSV, or custom formats. It allows data normalization and enrichment for downstream analysis. - Distributed Tracing and Debugging:
Fluentd supports distributed tracing, helping developers trace requests and identify performance bottlenecks or bugs in distributed systems. - Compliance and Auditing:
Fluentd is used to collect and process logs for compliance with industry regulations, ensuring that logs are stored, analyzed, and accessible for auditing purposes. - Event-driven Automation:
Fluentd can be integrated with automation tools to trigger actions based on specific events in the log data, such as alerting teams when an error rate exceeds a threshold.
Features of Fluentd
- Unified Logging Layer:
Fluentd provides a single platform to collect, process, and distribute logs from various sources and systems, simplifying log management. - Real-Time Data Processing:
Fluentd processes log in real-time, ensuring that organizations can respond quickly to issues and monitor system health continuously. - Highly Extensible:
Fluentd supports a large ecosystem of plugins, allowing users to customize input, output, and filtering processes to suit specific needs. - Fault Tolerance:
Fluentd provides built-in fault tolerance, ensuring that logs are not lost during network or system failures. It offers features like buffering and retry mechanisms. - Flexible Data Transformation:
Fluentd can parse and transform log data using a variety of filters such as JSON parsing, regex filtering, and data enrichment, making it easy to process and standardize logs. - Scalability:
Fluentd can handle large volumes of log data, making it suitable for enterprise-level applications and high-throughput environments. - Integration with Popular Log Management Systems:
Fluentd integrates well with popular systems like Elasticsearch, Kafka, HDFS, and cloud-based platforms such as AWS and Google Cloud, ensuring that data flows seamlessly to desired destinations. - Cloud-Native Support:
Fluentd is designed for cloud-native environments, and it works well with container orchestration systems like Kubernetes, Docker, and microservices architectures. - Lightweight and Resource-Efficient:
Fluentd is designed to be lightweight, using minimal resources while processing large amounts of log data. - Structured and Unstructured Log Support:
Fluentd can handle both structured logs (like JSON) and unstructured logs (like plain text), ensuring flexibility in data collection.
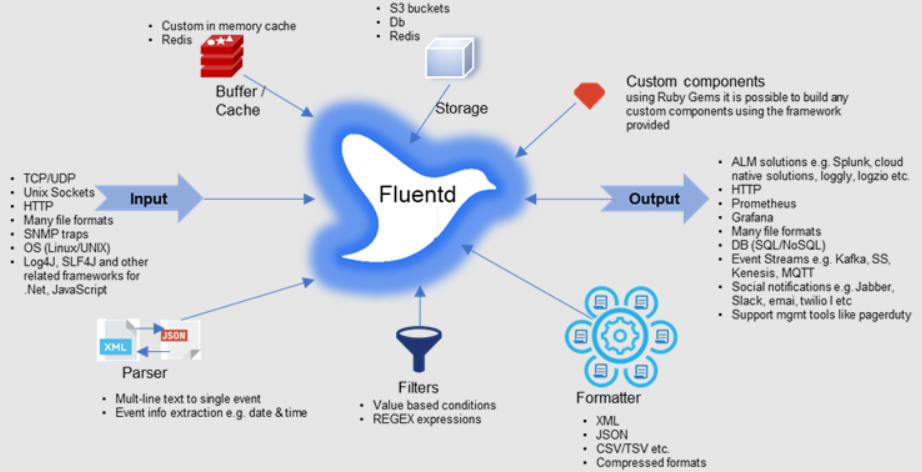
How Fluentd Works and its Architecture
Fluentd operates on a pipeline architecture that consists of three main components:
- Input Plugins:
Fluentd collects data from various sources using input plugins. These could be log files, HTTP endpoints, databases, or other data streams. - Filter Plugins:
Once data is collected, Fluentd applies filters to transform and enrich the data. This could involve parsing log formats, applying regex, or adding additional metadata. - Output Plugins:
Fluentd then sends the processed data to one or more output destinations, such as databases, data lakes, or analytics platforms.
The architecture is designed to be modular and scalable, allowing users to customize the flow of data as needed and ensure high availability and performance.
How to Install Fluentd
- Install Prerequisites:
Fluentd requires Ruby, so ensure Ruby is installed on your system. You can install it using package managers likeaptfor Ubuntu orbrewfor macOS. - Install Fluentd:
Fluentd can be installed using RubyGems or a package manager. To install via RubyGems, rungem install fluentdin your terminal. Alternatively, you can use system packages likeapt-getoryumto install Fluentd. - Configure Fluentd:
Fluentd uses a configuration file (fluent.conf) to define the pipeline. In this file, you specify the input sources, filter plugins, and output destinations. Customize it according to your use case. - Start Fluentd:
Once installed and configured, start Fluentd using the commandfluentd -c fluent.confto begin collecting and processing log data. - Monitor Fluentd:
Monitor Fluentd’s logs and performance to ensure that data is being processed and routed correctly.
Basic Tutorials of Fluentd: Getting Started
- Create Your First Fluentd Pipeline:
Define an input source, apply a simple filter (such as JSON parsing), and send the output to a destination like Elasticsearch or a file. - Use Filters to Transform Logs:
Learn how to parse unstructured logs and convert them into structured data formats like JSON using Fluentd’s powerful filters. - Configure Multiple Outputs:
Fluentd allows you to send log data to multiple destinations simultaneously, such as Elasticsearch for analysis and S3 for storage. - Monitor Fluentd’s Performance:
Fluentd provides built-in monitoring tools. Track the status of your log pipeline to ensure data is being processed efficiently and without loss.