Introduction
In the world of modern IT infrastructure, where uptime and availability are crucial to business success, the ability to detect, manage, and resolve incidents quickly is vital. VictorOps, now part of Splunk On-Call, is an advanced incident management and response platform designed to help DevOps, IT operations, and security teams handle critical incidents in real-time. By ensuring that the right people are notified instantly and that workflows are automated, VictorOps significantly improves incident response times, minimizes downtime, and keeps systems running smoothly.
In this blog, we will explore what VictorOps is, its key features, and examine how it is used by businesses to optimize their incident management processes. From real-time alerts to post-incident reporting, we will highlight the many ways in which VictorOps can help your team respond to and resolve issues efficiently.
What is VictorOps?
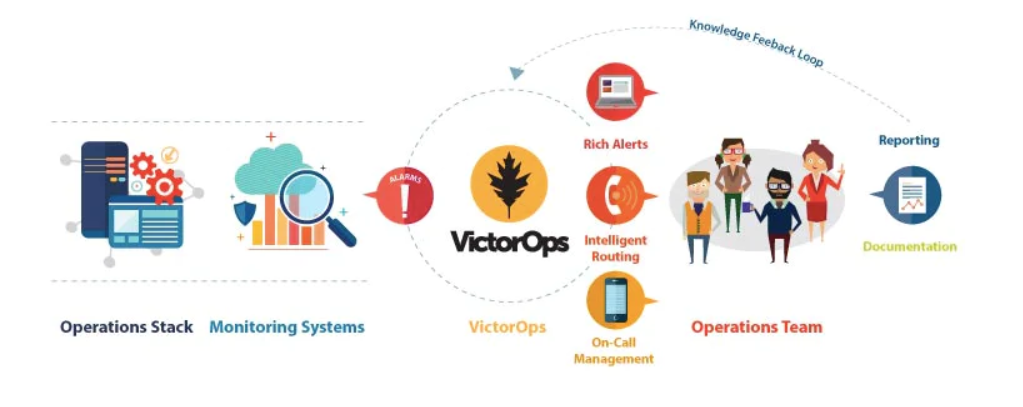
VictorOps is an incident management platform designed to facilitate collaboration and faster incident resolution for teams operating in dynamic environments. It centralizes alerts from various monitoring systems and automates the incident response process, ensuring that the right team members are notified immediately when issues arise. This leads to quicker resolution times, better visibility into the status of incidents, and improved communication between team members.
VictorOps integrates seamlessly with a wide range of monitoring, alerting, and collaboration tools, making it a valuable part of any organization’s IT infrastructure. By providing real-time visibility and detailed reporting on incidents, VictorOps helps organizations maintain high availability, improve performance, and reduce the risk of service disruptions.
Top 10 Use Cases of VictorOps
- Real-Time Incident Alerting
VictorOps excels in real-time incident alerting, ensuring that the right person is notified immediately when an issue is detected. Whether it’s an application error or a security breach, VictorOps makes sure the appropriate team members are informed instantly, minimizing downtime. - On-Call Management and Scheduling
VictorOps allows organizations to manage on-call schedules effectively. It automates the process of assigning and rotating on-call shifts, ensuring that the right people are available to respond to incidents at all times. - Incident Response Automation
With predefined workflows and automatic escalation policies, VictorOps streamlines the incident response process. If the first responder is unavailable or unable to resolve the issue, the platform automatically escalates the incident to the next tier of support, ensuring timely resolution. - Root Cause Analysis and Incident Tracking
VictorOps provides detailed tracking and reporting tools that help teams perform root cause analysis after incidents. By analyzing incident trends and root causes, teams can identify recurring issues and take steps to prevent future occurrences. - Collaboration and Communication
VictorOps facilitates collaboration by providing built-in chat and communication tools. Teams can work together to resolve issues faster, share updates in real time, and maintain clear communication during high-pressure incidents. - Integration with Monitoring Tools
VictorOps integrates with a wide range of monitoring systems like AWS CloudWatch, New Relic, Datadog, and Nagios. This allows teams to centralize all alerts and incidents in one place, providing a single point of visibility for monitoring and responding to issues. - Incident Escalation
With customizable escalation policies, VictorOps ensures that if an incident is not resolved within a certain timeframe, it is automatically escalated to higher-level teams or managers. This prevents incidents from being ignored and ensures timely resolution. - Security Incident Management
VictorOps plays a crucial role in managing security incidents. It integrates with security monitoring tools, ensuring that critical security alerts are identified and acted upon quickly to mitigate potential risks. - Performance Monitoring and Service Reliability
VictorOps is used to monitor system and application performance, ensuring that potential issues are flagged early. By proactively addressing performance degradation, organizations can improve system reliability and prevent larger incidents. - Post-Incident Reporting and Analytics
After an incident is resolved, VictorOps generates comprehensive post-incident reports, providing insights into how the incident was handled, what went well, and what could be improved. This data is essential for continuous improvement and refining incident management strategies.
Features of VictorOps
- Real-Time Alerts: VictorOps ensures immediate notification of incidents, sending alerts via multiple channels such as email, SMS, push notifications, and voice calls.
- Incident Tracking: VictorOps provides detailed incident tracking and visualization tools, allowing teams to monitor the status and progress of each incident in real time.
- Escalation Policies: With customizable escalation policies, VictorOps ensures that incidents are promptly addressed by the right person, even if the first responder is unavailable.
- On-Call Scheduling: VictorOps simplifies on-call scheduling and rotation, ensuring that the right personnel are always available to handle incidents.
- Automation: The platform offers automation features such as automated ticket creation, routing, and escalation, reducing manual tasks and response times.
- Collaboration: VictorOps includes built-in chat and collaboration tools, allowing teams to communicate efficiently during incident resolution.
- Integration: VictorOps integrates seamlessly with monitoring, alerting, and incident management tools, such as Jira, Slack, Datadog, and AWS CloudWatch.
- Post-Incident Analytics: The platform provides detailed reporting and analytics to help teams evaluate incident response times, identify trends, and improve their incident management processes.
How VictorOps Works and Its Architecture
VictorOps uses a centralized incident management system that integrates with various monitoring and alerting tools. When a problem occurs, VictorOps receives an alert and automatically triggers a response based on predefined escalation policies. The platform then notifies the relevant team members, who can use the platform’s communication tools to discuss and resolve the issue.
VictorOps operates on a modular architecture with three core components:
- Alerting: Integrates with monitoring tools to detect incidents and automatically trigger alerts.
- Incident Management: Manages the lifecycle of an incident, from detection to resolution, ensuring that it is handled in a timely manner.
- Collaboration: Provides real-time collaboration and communication tools to facilitate team coordination and incident resolution.
The platform uses customizable workflows, escalation policies, and on-call schedules to ensure that incidents are responded to efficiently and resolved as quickly as possible.
How to Install VictorOps
- Sign Up for VictorOps:
Go to the VictorOps website and sign up for an account. You can start with a free trial to explore the platform’s features. - Set Up Your Account:
After signing up, configure your account by setting up your organization’s name, time zone, and preferred notification settings. - Create On-Call Schedules:
Define your team’s on-call schedules and assign rotations to ensure coverage during all hours. - Integrate Monitoring Tools:
Connect VictorOps with your existing monitoring tools, such as Datadog, AWS CloudWatch, or New Relic, to automatically import alerts. - Define Escalation Policies:
Set up escalation rules to ensure that incidents are handled promptly and escalated if necessary. - Download the VictorOps App:
Install the VictorOps mobile app on your iOS or Android device to receive alerts and manage incidents on the go.
Basic Tutorials of VictorOps: Getting Started
- Create an Incident:
Start by creating a sample incident in VictorOps and assigning it to a team member for resolution. Learn how to monitor the incident’s progress and escalate it if needed. - Set Up Automation Rules:
Explore how to create automation rules that route incidents based on predefined criteria and escalate them when necessary. - Generate Reports:
Learn how to generate post-incident reports and use analytics tools to track response times and evaluate incident handling performance.